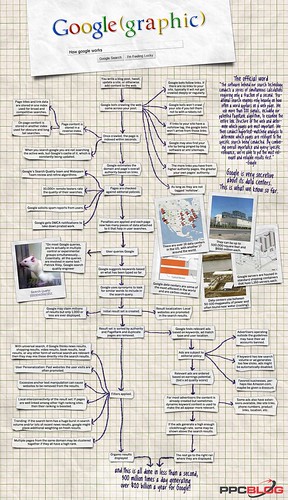
按小圖看大圖
這是網路上一張很有趣的圖,提供免責嵌入,這張圖把Google搜尋到底是如何運作的,手繪出來,過去我們對「搜索引擎最佳化」(Search engine optimization,SEO)、PageRank等是啥米碗榚,總是聽人講到霧煞煞,很多人也靠這行吃飯,這張圖,可以幫助客戶了解,至於當老師,更是可以拿來做基礎教學。所以我儘量把圖中的英文翻過來,並加上相關註解,但個人所知有限,如有差錯之處,歡迎指教。
當你寫好了一篇部落格文章、發出一則噗文(美國人用Twitter)、更新一個網站,或者添加內容到網路上,Google到處爬的機器人(Google Bots)就來接近你所貼的東西。這時候,出現第一個節點,先判斷六件事,決定搜尋的順序:
1.Google Bots會先追蹤連結,如果你的內容沒有連結,那就不會深入或被經常性的搜尋。
2.看你有沒有使用robots.txt文件,說明不想被檢索的部份(參考:「什麼是robots.txt文件?」),那麼Google Bots就不會搜尋你不想被找到的部份。
3.看你有沒有使用Nofollow標籤(Nofollow標籤的用法詳解),如果有,Google Bots就不會到達這些連結。
4. Google Bots還是有可能因為某些Ping到你的網站的部落格軟體或XML網站地圖的關係,而來進行搜尋。
5.如果有更多從「權威網站」(Authority Sites)(指的是如PageRank之類的評比,比方說,從PR較高旳網站連結到你的網頁,那麼就會被評比為較高的權威,但也不完全這樣,「集線性網站」(Hub Sites)也是被視為較高的位階)而來的連結,你的網頁就獲得越高的質量位階。(搜索引擎基本上分為定期派出蜘蛛(spider),發現新資料,即納入其數據庫;另一為版主或開發者主動提交,如Webmaster)
6. Google的官方說法,凡遇見任何連結有nofollow標籤,就會自動退回來,而進行另一個連結的爬行。
第二個節點,是凡被Google蜘蛛爬過的網頁都會被索引化,然後這時候會做兩個工作:一是網頁的內容會被儲存在可反向的索引(reverse index)裡,這時候,會進行兩個索引化:
1.是會將網頁內容和連結資料,存在一個更廣、更競爭性的索引數據資料庫裡。
2.是網頁內容也會被備份在一個比較隱晦和長尾效應的索引裡,以等待更進一步的搜尋。
其二是當你搜尋Google,並不是在正在活動的網頁上搜尋,而是到Google經常更新的「快取」(cache)上。
第三個節點,Google會主動評估該網域或網頁網址的權威重要性(這點是Google內部的運算,根據其排名算法、網頁中關鍵詞的匹配程度,出現的位置與頻率、連結值量等,計算出各個網頁的關聯度及排名等級,按順序將查詢結果送回去給檢索者)。
第四個節點,是檢查有無違反編輯政策(不是指言論自由),這時會有四個技術上的動作:
1.Google「搜尋品質」和「防止網路垃圾(Webspam)」團隊會先做運算上的審查。(這是根據許多技術運算作為標準,如果有興趣,可以參考「什麼是搜索引擎」這篇文章)
2.一萬次以上頻率的遠端測試結果。
3.Google徵求使用者的「網路垃圾」回報。
4.根據美國「千禧年數位著作權決議」(Digital Millennium Copyright Act, DMCA)原則,保護原著作人之權益。
第五個節點是經過了這一切旳運算「檢查」後,去蕪存菁來幫助搜尋。
第六個節點是使用「呼叫」(Query) Google。(這點請參考「Qurey類別」一文)
第七個節點是Google依已經被類型化的資料建議關鍵字。
第八個節點是Google使用同義詞去搜尋相似的字詞呼應搜尋。
第九個節點是初始化的結果被創造出來,此時Google可能找到數百萬個結果,但可能只有一千個或更少被呈現出來;結果在地化,也就是優先呈現在地內容。
第十個節點結果組合是依權重後的權威及PageRank,並去除掉重複者來排列。此時Google會同時進行幾項工作:
1.Google會依關鍵字、廣告搭配類型、在地位址找出相關廣告。
2.廣告也是符合Google的編輯政策。關於這點,還有三個原則:首先是一旦廣告者操作悖離Google的指導原則,那帳戶就會被禁止;其次,如果廣告的關鍵字是太少人搜尋或點擊,那麼這廣告就可能會被自動停刊;最後是大眾喜愛的網站,如亞馬遜,可能會提供折扣。
3.根據出價和品質分數等獲利潛力,相關的廣告會被點叫。
4. 對廣告者來說,他們雖然已創造好內容,但動態的關鍵字內容,也會被用來出現相關的廣告。有些廣告則做了一些延伸,如網站連結、電話號碼、產品連結、地址等。
5.如果廣告的效率高,有些會被提上來出現在檢索結果的上方。
6.其餘的回歸正軌。
第十一個節點是過濾應用。包含六項:
1.因為全面性的搜尋,如果Google認為新聞、購物、影片、書籍、在地等結果,或其他垂直檢索的結果是相關的,那麼就可能會混和著一起出現。
2.使用者個人化,使用者造訪過的網站,會優先出現。
3.過多的「連結錨文本」(Anchor Text)操作,可能導致網站出現在搜尋結果裡。
4.本地互聯結果組合:如果網站和其他高PR的網站連結得很好,那麼排名就會往前。
5. 趨勢:如果搜尋項目忽然出現大量搜尋,或者,而且,有大量相關最新新聞結果,那麼Google就會對這些新鮮的結果加上特別的權重。
6.具有多重網頁,而相同網域,且PR值高的,會被歸在一起。
講得這麼多,以上這些Google運算程序都少於一秒內完成,每日運作三億次以上,每年超過兩百億次。